定义
旨意是位分布一系列任务到到一系列资源进行处理,目的是为了提高处理效率 关于任务,需要考虑任务的执行时间 任务的大小,任务依赖(任务调度metaheuristic),任务分发(Tree-Shaped Computation),这个决定了执行时间
算法
静态算法
不需要考虑处理任务的处理状态,分发给计算单元就行,也是有一定统计每个计算单元的任务量,优点是使用简单 代表算法 1、轮询请求(Round robin), 想象成一个循环链表,指针代表当前访问的节点,接收任务一次,指针移动一次指向下一个
2、随机请求(random),也就是随机函数挑选一个,也可以加上权重 3、哈希请求(hash), 通过hash函数,指派任务到某一组计算单元 4、权重(weight),设置计算单元,那些可以接收多些任务进行选取请求,这个也可以结合 轮询,会使分配更加均衡 5、最小工作(连接)请求(less,work) , 最小请求的计算单元,指派更多任务
动态算法
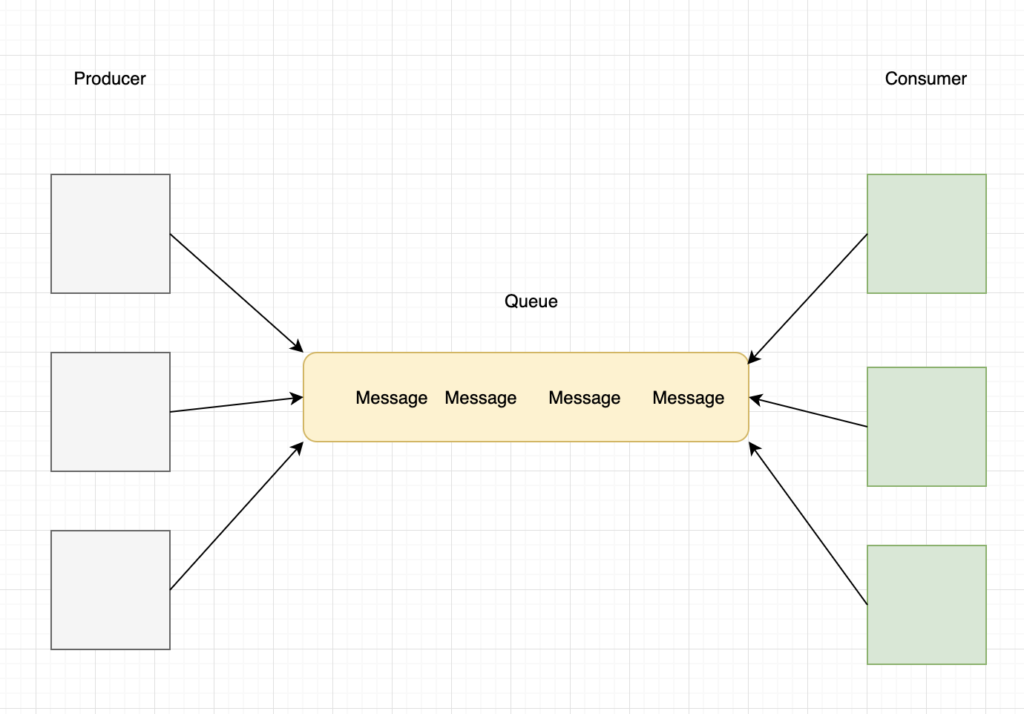
不同的计算单元需要交换状态信息,但效率会比较低需要收集多个计算单元负载情况 代表算法 Master-worker 通过一个主指派任务给每个worker,面对大量任务master 会称为瓶颈
非分层架构,个master-worker 相反,它利用一种叫做work stealing 的方式,指某个线程从其他队列里窃取任务来执行,这种思想是因为有些线程给某些线程更快处理完任务,可以把另外线程的任务队列拿来进行处理 在某些情况下还是会存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗更多的系统资源, 比如创建多个线程和多个双端队列。 Work stealing 最大效益的是,每个任务计算不需要依赖其它任务完成,不然就变等待,这样效率也不会变高
平均负载算法,
收集每个节点的负载情况,首先计算出集群各个节点的负载富余的平均值,然后求方差,如果结果越小则说明集群负载越均衡,状态越健康,越大则说明越不均衡,集群的负载均衡处于一个相对不健康的状态 基于网络响应时间(mongodb客户端),基于网络我们需要考虑 可信度问题,也就是需要考虑网络波动问题 例如:m0离当前时间最近,认为m0的可信度最高,所以给了36%的权重
基于负载值
例如:m表示计算得到的负载值,m0表示当前获取到的节点负载,m1表示上一秒获取到的节点负载,参数D是可信度系数,表示上一秒的节点负载值对当前负载值的影响程度,越大表示影响越小
并行硬件负载均衡设计 硬件并行计算任务需要考虑 1、异构计算机组成 2、共享与分布式内存,通过分布式内存与消息通知协调处理单元 3、分层处理”Master-Worker”,通过这个模式,master 指派任务到不同的计算单元硬件上 4、易扩展 5、容错
基于网络层面考虑
四层(TCP 和 UDP)是基于连接做流量调度,TCP Keepalive 保持长连接 七层(HTTP/HTTPS)是基于请求做调度。比如 http get 请求访问一个页面。 四层 vs 七层 四层,客户端和Real Server仅仅只建立了一条连接,负载均衡器仅仅只起着转发这样的一个功能,只不过在转发的过程当中将IP报文头做个修改。但是连接始终还是一条连接 七层,负载均衡器对负载均衡要求更加高,因为一个正常连接都会建立两条独立的TCP连接。由于建立了两条TCP连接 七层返回数据模式:Real Server将请求处理完毕之后纯粹的将请求发回给负载均衡处理,负载均衡处理器再将请求转发给客户端,正常的TCP连接基于七层的,进要经过负载均衡器出也要经过负载均衡器,就是进出都要经过负载均衡器 四层返回数据模式:请求客户端到达服务端之后,服务端响应返回数据有两种方式。一种是直接将数据返回给客户端,而不经过中间的四层负载均衡器,这是经常使用的DR方式
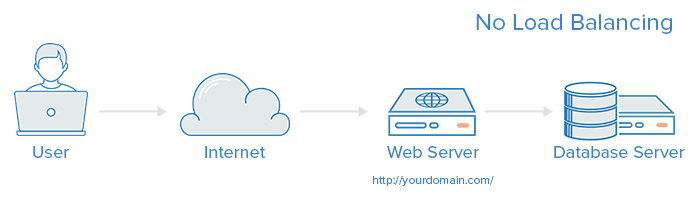
负载均衡系统设计特点
请求的分发
静态算法 动态算法
会话保持
源IP地址的持续性保持 cookie 持续性保持 基于HTTP报文头的持续性保持
服务健康监测
利用ICMP、TCP、HTTP、FTP等协议进行检测,即主要是在传输层和应用层进行检测
故障隔离 出现问题剔除
自动恢复 自动注册
均衡的应用
DNS负载均衡(DNS RR记录)全局负载均衡(GSL.B,Global Server Load Balance)主要的目的是在整个网络范围内将用户的请求定向到最近的节点(或者区域) 基于DNS实现、基于重定向实现、基于路由协议实现 特点:能通过判断服务器的负载,包括CPU占用、带宽占用等数据,决定服务器的可用性,同时能判断用户(访问者)与服务器间的链路状况,选择链路状况最好的服务器
优点使用简单:负载均衡工作,交给DNS服务器处理,省掉了负载均衡服务器维护的麻烦提高性能:可以支持基于地址的域名解析,解析成距离用户最近的服务器地址,可以加快访问速度,改善性能; 缺点可用性差:DNS解析是多级解析,新增/修改DNS后,解析时间较长;解析过程中,用户访问网站将失败;扩展性低:DNS负载均衡的控制权在域名商那里,无法对其做更多的改善和扩展;维护性差:也不能反映服务器的当前运行状态;支持的算法少;不能区分服务器的差异(不能根据系统与服务的状态来判断负载)
IP负载均衡(反向代理)在网络层通过修改请求目标地址进行负载均衡 真实服务器处理完成后,响应数据包回到负载均衡服务器,负载均衡服务器,再将数据包源地址修改为自身的ip地址,发送给用户浏览器 IP负载均衡,真实物理服务器返回给负载均衡服务器,存在两种方式:
(1)负载均衡服务器在修改目的ip地址的同时修改源地址。将数据包源地址设为自身盘,即源地址转换(snat)。
(2)将负载均衡服务器同时作为真实物理服务器集群的网关服务器。
优点:
(1)在内核进程完成数据分发,比在应用层分发性能更好;
缺点:
(2)所有请求响应都需要经过负载均衡服务器,集群最大吞吐量受限于负载均衡服务器网卡带宽;
链路层负载均衡
数据分发时,不修改ip地址,指修改目标mac地址,配置真实物理服务器集群所有机器虚拟ip和负载均衡服务器ip地址一致,达到不修改数据包的源地址和目标地址,进行数据分发的目的。 实际处理服务器ip和数据请求目的ip一致,不需要经过负载均衡服务器进行地址转换,可将响应数据包直接返回给用户浏览器,避免负载均衡服务器网卡带宽成为瓶颈。也称为直接路由模式(DR模式) DR模式 意思是 后端服务直接跟服务端进行数据交互 实现方式,多个后端服务器 + 一个入口(LVS)形成一个VIP入口,然后入口接收请求,转发给后端服务器(端口需要一致 客户访问80,后端服务也是80)然后入口把mac地址改为客户端把包交给后端服务器,通过修改数据包进行数据均衡,这个时候入口会记录这个配对
负载均衡请求不均衡的原因
1、长链某些节点 2、后端某些节点响应异常 如 开启了会话保持功能 健康检查异常 TCP Keepalive 保持长连接
加权最小连接数(WLC)调度方式和会话保持 -> 尝试改为加权加权轮询(WRR)算法和会话保持
https://developer.qiniu.com/qvm/kb/5144/the-common-problems-in-load-balancing
工具
分类
七层代理 nginx haproxy
四层代理 lvs,haproxy, F5
CDN,分布式内容
解析
LVS
是基于Linux操作系统实现的一种软负载均衡,四层的IP负载均衡技术 LVS+Keepalived 对 MySQL 主从做负载均衡
LVS的优点 抗负载能力强、是工作在网络4层之上仅作分发之用,没有流量的产生,这个特点也决定了它在负载均衡软件里的性能最强的,对内存和cpu资源消耗比较低 缺点 软件本身不支持正则表达式处理,不能做动静分离;而现在许多网站在这方面都有较强的需求,这个是Nginx/HAProxy+Keepalived的优势所在
HAProxy
补充Nginx的一些缺点,比如支持Session的保持,Cookie的引导;同时支持通过获取指定的url来检测后端服务器的状态。 支持TCP协议的负载均衡转发,可以对MySQL读进行负载均衡,对后端的MySQL节点进行检测和负载均衡,大家可以用LVS+Keepalived对MySQL主从做负载均衡
HAProxy 是基于第三应用实现的软负载均衡,Haproxy 是基于四层和七层技术 HAProxy 负载均衡策略非常多:Round-robin(轮循)、Weight-round-robin(带权轮循)、source(原地址保持)、RI(请求URL)、rdp-cookie(根据cookie)static-rr,表示根据权重
Nginx
Nginx 优点:基于系统与应用的负载均衡,能够更好地根据系统与应用的状况来分配负载 缺点:负载能力受服务器本身性能的影响,仅能支持http、https和Email协议
Nginx 实现负载均衡的分配策略, 轮询(默认):weight:指定轮询几率。 ip_hash:每个请求按访问 ip 的 hash 结果分配。 fair(第三方):按后端服务器的响应时间来分配请求,响应时间短的优先分配。 url_hash(第三方):按访问 url 的 hash 结果来分配请求,使每个 url 定向到同一个后端服务器,后端服务器为缓存时比较有效。
F5
优点:能够直接通过智能交换机实现,处理能力更强,而且与系统无关,负载性能强,更适用于一大堆设备、大访问量、简单应用。
缺点:成本高,除设备价格高昂,而且配置冗余,很难想象后面服务器做一个集群,但最关键的负载均衡设备却是单点配置,无法有效掌握服务器及应用状态。负载均衡功能
F5 BIG-IP用作HTTP负载均衡器的主要功能:
1、F5 BIG-IP提供12种灵活的算法将所有流量均衡的分配到各个服务器,而面对用户,只是一台虚拟服务器。
2、F5 BIG-IP可以确认应用程序能否对请求返回对应的数据。假如F5 BIG-IP后面的某一台服务器发生服务停止、死机等故障,F5会检查出来并将该服务器标识为宕机,从而不将用户的访问请求传送到该台发生故障的服务器上。这样,只要其它的服务器正常,用户的访问就不会受到影响。宕机一旦修复,F5 BIG-IP就会自动查证应用保证对客户的请求作出正确响应并恢复向该服务器传送。
3、F5 BIG-IP具有动态Session的会话保持功能,笔者也是在网站中使用的F5将用户IP与Session通过F5进行的绑定,使其Session保持一致。
4、F5 BIG-IP的iRules功能可以做HTTP内容过滤,根据不同的域名、URL,将访问请求传送到不同的服务器。
https://zhuanlan.zhihu.com/p/71825940https://www.haproxy.com/blog/layer-4-load-balancing-direct-server-return-mode/
应用场景
DNS 轮询算法,一个域名有多个IP解析 反向代理 nginx php-fpm master work方式
问题
1、对于负载均衡的后端服务,有两个节点A,B,在长链的情况下,他们的连接数都很平均,如果某个出现故障这个时候,如A 故障后,它的连接都转移到B上,这个时候A恢复,怎样平衡回去
这个问题如果是处理任务还可以通过work steal方式来处理这个问题,但是如果是长连接的话,需要在负载均衡上面通过修改最小连接或者加权来慢慢把B的连接追上,而不是轮询打到A上,因为此时A已经好高连接数了
长连接的优势
要点 跟短链接对比,避免重新协商 SSL,避免回话建立 考虑点 1、线路带宽 2、机器负载
解决方式 可以基于网络连接时间 与 每个机器的负载,取权重且计算出方差去挑选那个节点比较优
如 流媒体内容的质量仍然取决于用户的连接速
https://www.open-open.com/lib/view/open1426302583482.html
案例
阿里巴巴为什么能抗住90秒100亿? https://zhuanlan.zhihu.com/p/338884995
亿级Web系统搭建 Web负载均衡的几种实现方式(阿里) https://www.cnblogs.com/aspirant/p/11607839.html
资料
论文 https://en.wikipedia.org/wiki/MetaheuristicHierarchical Work-Stealing https://hal.inria.fr/inria-00429624v2/documentOn the Scalability of Constraint Programming on Hierarchical Multiprocessor Systems https://dspace.uevora.pt/rdpc/bitstream/10174/10653/1/icpp2013.pdf
Scheduling Multithreaded Computations by Work Stealing http://supertech.csail.mit.edu/papers/steal.pdfTree-Shaped computation Tree Shaped Computations as a Model for Parallel Applications https://en.wikipedia.org/wiki/Distributed_tree_searchTree Shaped Computations as a Model for Parallel Applications San98b.pdf https://en.wikipedia.org/wiki/Distributed_tree_searchhttps://en.wikipedia.org/wiki/Round-robin_schedulinghttps://en.wikipedia.org/wiki/Message_passinghttps://en.wikipedia.org/wiki/Distributed_shared_memoryhttps://en.wikipedia.org/wiki/Distributed_cachehttps://en.wikipedia.org/wiki/Load_balancing_(computing)#Non-hierarchical_architecture,_without_knowledge_of_the_system:_work_stealing
http://www.uml.org.cn/zjjs/201807091.asp
https://zhuanlan.zhihu.com/p/31777732
Web后端系统架构漫谈(1)——负载均衡 https://nullcc.github.io/2017/11/23/Web%E5%90%8E%E7%AB%AF%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E6%BC%AB%E8%B0%88(1)%E2%80%94%E2%80%94%E8%B4%9F%E8%BD%BD%E5%9D%87%E8%A1%A1/
六大Web负载均衡原理与实现 https://www.cnblogs.com/aspirant/p/9087716.html
LVS集群中的IP负载均衡技术 https://cloud.tencent.com/developer/article/1031890https://www.cnblogs.com/aspirant/p/9084740.html
负载均衡的原理和实现细节 – 代码 https://dubbo.apache.org/zh/docs/v2.7/dev/source/loadbalance/全局负载均衡GSLB https://jjayyyyyyy.github.io/2017/05/17/GSLB.htmlhttps://www.efficientip.com/what-is-gslb/